















Gunakan Teknologi Teks ke Suara untuk Menghasilkan Narasi pada Video

Dalam sebuah video, biasanya terdapat narasi untuk membimbing penonton atau suara karakter saat mereka terlibat dalam percakapan. Selain berbagai narasi yang ditawarkan oleh para pengisi suara profesional, muncul alternatif baru dengan kekuatan Teknologi Teks ke Suara (TTS) teknologi. Artikel ini akan membimbing Anda melalui kemampuan luar biasa Teknologi Teks ke Suara dalam VP Animated Explainer, menunjukkan bagaimana teknologi ini mengubah teks tertulis menjadi narasi dinamis dan hidup untuk video Anda.
Apa itu Teknologi Teks ke Suara (TTS)
Teknologi Teks ke Suara (TTS)teknologi, juga dikenal sebagai sintesis suara, adalah inovasi digital yang mengubah teks tertulis menjadi bahasa lisan. Teknologi canggih ini menggunakan algoritma kompleks untuk menganalisis dan memproses teks, menghasilkan audio yang alami dan ekspresif.
TTS dirancang untuk meniru irama, nada, dan intonasi ucapan manusia, menghasilkan narasi yang hidup yang dapat diterapkan dalam berbagai aplikasi, mulai dari alat aksesibilitas bagi penyandang tunanetra hingga asisten suara dan interaksi layanan pelanggan otomatis. Teknologi TTS tidak hanya efisien, tetapi juga membuka dunia kemungkinan dalam pembuatan konten, menjadikannya alat yang serbaguna dan tak tergantikan dalam lingkungan digital saat ini.
Gunakan Teknologi Teks ke Suara untuk Menghasilkan Narasi pada Video
Di VP Animated Explainer, pilih teks ke suara di bawah Jenis Audio. Kemudian masukkan ucapan Anda ke kotak teks di bawah ini. Kemudian klik Pilih Pembicara.
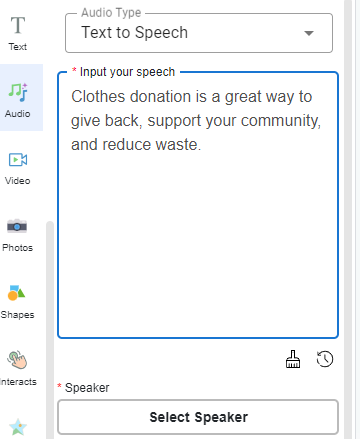
Anda dapat memilih pembicara dengan berbagai jenis kelamin dan bahasa. Klik tombol putar pada pembicara untuk mendengarkan nada dan suaranya secara preview. Setelah itu, klik Konfirmasi Pilihan tombol.
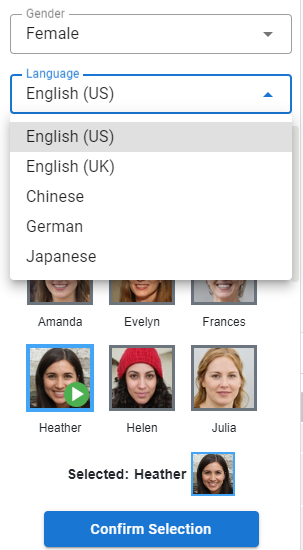
Tekan tombol Hasilkan tombol untuk menghasilkan narasi dari naskah Anda. Setelah selesai, Anda dapat menekan tombol putar pada narasi yang dihasilkan untuk mendengarkan preview-nya, dan tekan tombol tambah untuk menambahkannya ke timeline video Anda.
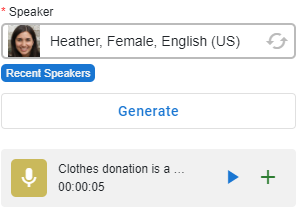
Klik kanan audio di timeline dan sesuaikan jika diperlukan.
5 Manfaat Menggunakan Teknologi Teks ke Suara dalam Karya Kita

Teknologi Teks ke Suara semakin umum digunakan di berbagai bidang. Mari kita bahas manfaat dari mengadopsi teknologi ini dan mengapa teknologi ini semakin populer:
- Efisiensi:Teknologi Teks ke Suara adalah keajaiban yang menghemat waktu. Dengan mengotomatisasi konversi teks tertulis menjadi konten lisan, teknologi ini mengurangi beban pekerjaan pencipta dalam merekam audio secara manual. Efisiensi ini memungkinkan produsen konten untuk fokus pada kualitas naskah dan ide mereka, bukan pada logistik penyampaian suara.
- Konsistensi:Konsistensi adalah kunci dalam branding dan pesan. Dengan Teknologi Teks ke Suara, Anda dapat menjaga nada dan gaya suara yang seragam di berbagai jenis konten. Baik itu modul pembelajaran elektronik, materi pemasaran, atau respons dukungan pelanggan, teknologi ini memastikan bahwa suara merek Anda tetap stabil dan mudah dikenali.
- Aksesibilitas:Teknologi Teks ke Suara adalah penjaga aksesibilitas. Ia mendemokratisasi konten dengan menyediakan versi suara dari teks, sehingga membuatnya inklusif bagi audiens yang lebih luas. Fitur ini merupakan perubahan besar bagi individu yang memiliki gangguan penglihatan, memastikan mereka dapat mengakses dan menikmati konten tertulis melalui narasi audio.
- Kustomisasi:Teknologi Teks ke Suara menawarkan tingkat kustomisasi yang sangat tinggi. Pengguna dapat memilih dari berbagai suara dan menyesuaikan parameter seperti nada, kecepatan, dan intonasi agar gaya suara sesuai dengan kebutuhan dan preferensi audiens tertentu. Tingkat kustomisasi ini memastikan bahwa konten lisan selaras sempurna dengan pesan yang dimaksudkan dan kepribadian merek, memberikan sentuhan unik pada narasi.
- Skalabilitas:Saat kebutuhan konten Anda berkembang, Teknologi Teks ke Suara berkembang bersama Anda. Teknologi ini sangat cocok untuk proyek yang memiliki permintaan audio yang besar, seperti platform pembelajaran elektronik dan buku audio. Ia menyediakan skalabilitas yang dibutuhkan untuk menghasilkan volume besar konten audio dengan mudah, tanpa mengorbankan kualitas atau kecepatan pengiriman.