















合并还是拆分?使用 Visual Paradigm Online 的 AI 图像翻译器,专业处理多行文本
说到图像文本翻译,其中最具挑战性的难题之一就是处理多行文本。无论你处理的是扫描的诗歌、多语言标签,还是杂乱的图表,文本的解读方式可能决定项目的成败。这时,Visual Paradigm Online便登场了,凭借其前沿的AI 图像翻译器,一款强大的AI 驱动的图像工具,旨在让您完全掌控自己的多语言图像翻译需求。在本文中,我们将深入探讨两个突出功能——合并文本块以及拆分合并的文本块——并展示它们如何让你的图像转文本翻译流程如专业人士般焕然一新。
图像翻译技术中的多行文本挑战
想象一下,你上传了一张图片,使用AI 图像转换技术进行翻译,而文本跨越了多行。有时,AI 视觉翻译器可能会将诗歌的两行误认为是独立的实体,或将两个不同的标签合并成一个令人困惑的块。这是AI 图像处理中常见的障碍,其中先进的AI 图像识别必须判断:这是被分成多行的单一段落,还是独立的内容片段?幸运的是,借助Visual Paradigm Online 的 AI 图像翻译器,你无需接受默认的解读。我们的工具赋予你图像语言翻译通过“合并”和“拆分”功能实现精准处理。
功能亮点:合并文本 文本块借助人工智能驱动的精准处理
假设你正在使用我们的AI图像翻译器.
原文如下:

经过我们的图像翻译技术之后,AI视觉翻译器可能会将它们视为两个独立的文本块,分别进行翻译。但如果它们本应作为一个连贯的整体表达呢?借助合并文本块功能,你可以选中这两行,将其合并为一个文本块,并触发重新翻译。结果如何?一次优美统一的翻译,完整保留了诗歌的原意,这一切都得益于AI图像处理的极致表现。

这一功能对需要多语言图像翻译以保持上下文完整性的写作者、教育工作者和设计师而言是革命性的。无论你是本地化创意内容,还是优化翻译文档,合并文本块都能确保你的图像转文本翻译忠实于原始内容。
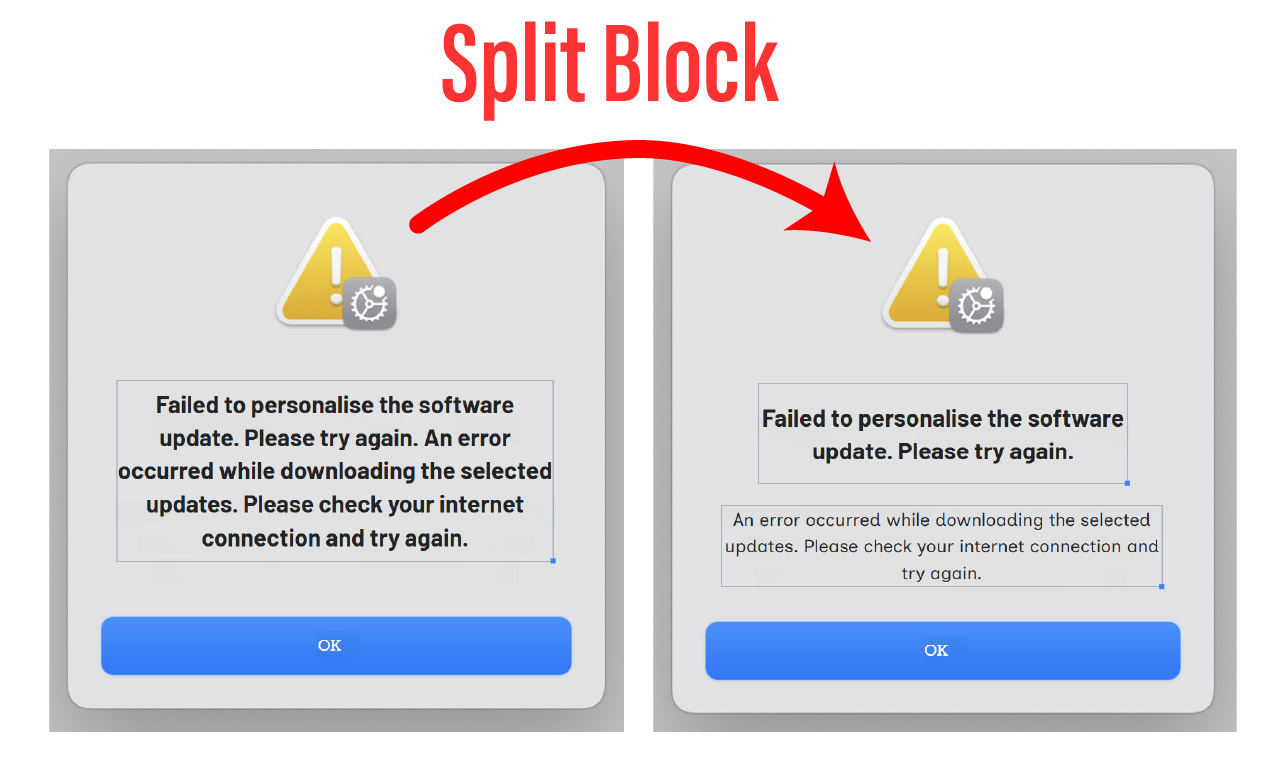
功能亮点:拆分合并的文本块以提升清晰度
如果AI图像翻译器在图像语言翻译过程中错误地将它们合并为一个文本块,翻译结果可能会变得混乱不堪。别担心——我们的拆分合并的文本块 该功能让您掌控一切。只需选择合并的文本块,将其拆分为两部分,然后观看 人工智能驱动的图像工具 准确地重新翻译每一部分。这对于调整布局的设计师或准备清晰多语言讲义的教育工作者来说再合适不过了。
哪些人能从这些功能中受益?
该合并文本块 和 拆分合并的文本块 功能专为任何重视在 图像文本翻译 中精确性的人量身定制。作家可以确保诗意的翻译自然流畅。教育工作者可以在不损失清晰度的情况下调整多语言资源。设计师可以使用 人工智能图像转换 来完善面向全球受众的布局。无论您的角色是什么, Visual Paradigm Online 的人工智能图像翻译器 使 多语言图像翻译 轻松且专业。
为什么选择 Visual Paradigm Online 进行人工智能图像翻译?
与基础工具不同,我们的 人工智能视觉翻译器 超越了简单的 图像到文本的翻译。通过合并和拆分文本块等功能,您不仅仅是翻译——您是在创作。基于先进的 图像翻译技术,这款 人工智能驱动的图像工具 支持超过 40 种语言,并提供无与伦比的灵活性。准备好尝试了吗?访问 https://ai.visual-paradigm.com/ai-image-translator,看看它如何提升您的 人工智能图像处理 工作流程。
轻松掌握多行文本
处理多行文本不必成为难题。无论您需要合并诗行还是拆分错误合并的标签,Visual Paradigm Online 的 AI 图像翻译器都能满足您的需求。它不仅仅是一个AI 图像识别工具——它是您打造精致、专业翻译的合作伙伴。那么,您将如何利用这些功能来简化您的下一个图像语言翻译项目呢?欢迎在评论中告诉我们!
