















Użyj przekształcania tekstu na mowę, aby wygenerować narrację do filmu

W filmie zwykle znajduje się narracja, która prowadzi widza, albo dźwięk dla postaci, gdy uczestniczą w rozmowach. Poza różnorodnymi narracjami oferowanymi przez profesjonalnych artystów dubbingu, pojawiła się alternatywna droga dzięki mocy Przekształcanie tekstu na mowę (TTS) technologii. Niniejszy artykuł przeprowadzi Cię przez niezwykłe możliwości przekształcania tekstu na mowę w VP Animated Explainer, pokazując, jak przekształca tekst pisany w dynamiczną, realistyczną narrację do Twoich filmów.
Co to jest technologia przekształcania tekstu na mowę (TTS)
Przekształcanie tekstu na mowę (TTS)Technologia przekształcania tekstu na mowę, znana również jako syntezator mowy, to transformacyjna innowacja cyfrowa, która przekształca tekst pisany w mowę. Ta nowoczesna technologia wykorzystuje złożone algorytmy do analizy i przetwarzania tekstu, przekształcając go w naturalny i wyrazisty dźwięk.
TTS została zaprojektowana w taki sposób, by imitować rytm, tonację i intonację mowy ludzkiej, tworząc realistyczne narracje, które mogą być wykorzystywane w różnych zastosowaniach – od narzędzi dostępności dla osób niewidomych po asystentów głosowych i automatyczne interakcje w obsłudze klienta. Technologia TTS nie tylko jest wydajna, ale także otwiera nowe horyzonty w tworzeniu treści, czyniąc ją uniwersalnym i niezastąpionym narzędziem w dzisiejszej przestrzeni cyfrowej.
Użyj przekształcania tekstu na mowę, aby wygenerować narrację do filmu
W VP Animated Explainer wybierz przekształcanie tekstu na mowę w sekcji Typ dźwięku. Następnie wpisz swoją mowę do pola tekstowego poniżej. Następnie kliknij Wybierz mówcę.
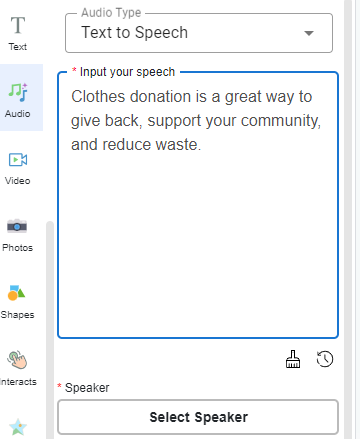
Możesz wybrać mówcę w różnych płciijęzykach. Kliknij przycisk odtwarzania u mówcy, aby przewinąć jego tonację i głos. Następnie kliknij Potwierdź wybór przycisk.
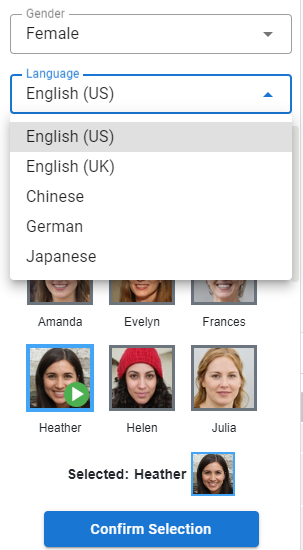
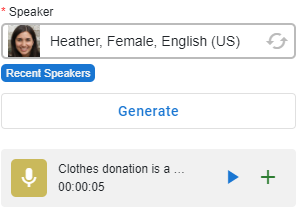
Naciśnij przycisk Generuj przycisk, aby wygenerować narrację z Twojego scenariusza. Po zakończeniu możesz nacisnąć przycisk odtwarzania w wygenerowanej narracji, aby ją przewinąć, a następnie nacisnąć przycisk Dodaj, aby dodać ją do linii czasowej filmu.
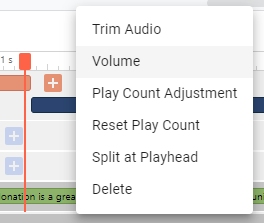
Kliknij prawym przyciskiem myszy dźwięk na linii czasowej i dostosuj go, jeśli to konieczne.
5 korzyści z wykorzystania technologii przekształcania tekstu na mowę w naszej pracy

Technologia przekształcania tekstu na mowę staje się coraz bardziej powszechna w różnych dziedzinach. Przejdźmy do zalet tej technologii i dlaczego zdobywa popularność:
- Efektywność:Technologia przekształcania tekstu na mowę to cud oszczędzania czasu. Automatyzując przekształcanie tekstu pisanej w mowę, pozwala twórcy na uniknięcie ciężkiej pracy związanej z ręcznym nagrywaniem dźwięku. Ta efektywność pozwala producentom treści skupić się na jakości swoich scenariuszy i pomysłów, a nie na logistyce przekazywania głosu.
- Spójność:Spójność to klucz w brandingu i komunikacji. Dzięki technologii Text to Speech możesz utrzymać jednolity ton głosu i styl w szerokim zakresie treści. Niezależnie od tego, czy chodzi o moduły e-learningowe, materiały marketingowe czy odpowiedzi w obsłudze klienta, ta technologia zapewnia, że głos marki pozostaje stabilny i łatwo rozpoznawalny.
- Dostępność:Text to Speech jest zwolennikiem dostępności. Demokratyzuje treści, oferując wersje mówione tekstu, co czyni je bardziej dostępnymi dla szerszej grupy odbiorców. Ta funkcja jest przełomem dla osób z niedowidzeniem, zapewniając im dostęp do i przyjemność z treści pisanych poprzez narrację dźwiękową.
- Dostosowanie:Technologia Text to Speech oferuje wysoki poziom dostosowania. Użytkownicy mogą wybierać spośród różnych głosów i dostosowywać parametry takie jak wysokość tonu, prędkość i intonacja, aby dopasować styl głosowy do konkretnych potrzeb i preferencji swojej publiczności. Ten poziom dostosowania gwarantuje, że treści mówione są zgodne z zamierzonym przekazem i osobowością marki, dodając unikalny odcień narracji.
- Skalowalność:Wraz z rozwojem potrzeb treści, Text to Speech rośnie razem z tobą. Ta technologia jest szczególnie odpowiednia dla projektów o dużych wymaganiach audio, takich jak platformy e-learningowe czy audioksiążki. Zapewnia skalowalność potrzebną do łatwego tworzenia dużych ilości treści dźwiękowych, bez kompromitowania jakości ani szybkości dostarczania.
