

Unifying OpenDocs, Pipelines, and AI Platforms for Scalable Technical Knowledge
In modern software engineering, documentation has evolved far beyond static markdown files or isolated wiki pages. It is now a dynamic, interconnected web of living artifacts: rapidly generated AI drafts, visually polished layouts, semantically validated architecture maps, and version-controlled source files. As organizations increasingly embed AI into their documentation workflows, the challenge shifts from generation to governance. How do you maintain a single source of truth across multiple platforms, prevent data drift, and ensure that published documentation always reflects the latest architectural intent?
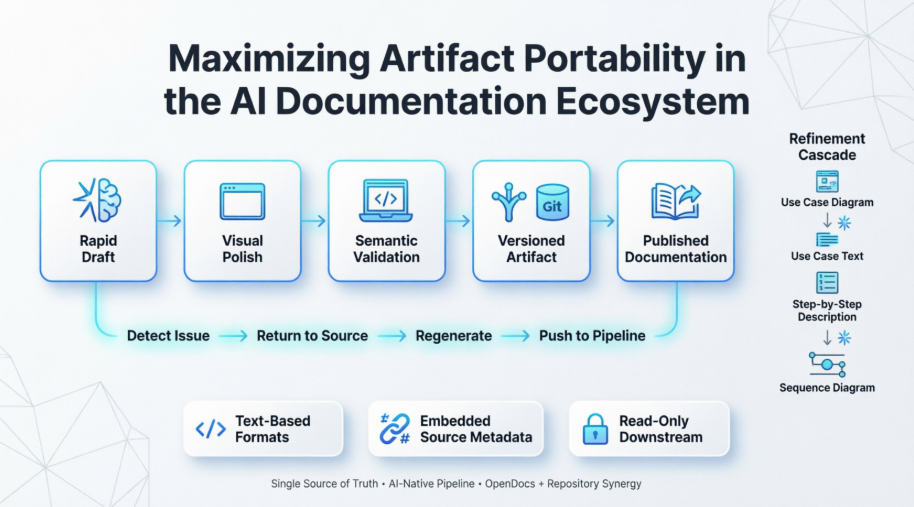
The answer lies in a disciplined, AI-native pipeline anchored by Pipeline Repository systems and OpenDocs publishing engines. This article outlines a comprehensive blueprint for maximizing artifact portability across the AI documentation ecosystem, emphasizing Just-in-Time (JIT) source modification, progressive refinement cascades, and cross-platform interoperability.
🔄 The AI-Generated Pipeline Flow
The modern documentation lifecycle is no longer linear; it is a specialized, multi-stage toolchain where each platform handles a distinct phase of artifact maturation. By orchestrating these stages into a seamless flow, teams can scale documentation without sacrificing accuracy.
[AI Chatbot] ➔ [Online Editor] ➔ [Desktop App] ➔ [Pipeline Repository] ➔ [OpenDocs]
(Rapid Draft) (Visual Polish) (Semantic Check) (Versioned Artifact) (Published Doc)
| Stage | Role in the Ecosystem | Key Output |
|---|---|---|
| 1. AI Chatbot | Rapid Draft Generation | Raw structural outlines, prompt-driven concept mapping |
| 2. Online Editor | Visual Polish & Layout | Web-formatted markdown, styled tables, quick UI tweaks |
| 3. Desktop App | Semantic & Architectural Validation | Deep logic testing, dependency verification, local rendering |
| 4. Pipeline Repository | Version Control & CI/CD | Git-tracked, production-ready source files, automated build artifacts |
| 5. OpenDocs | Published Knowledge Base | User-facing, searchable, versioned documentation site |
This pipeline ensures that every artifact passes through a maturity curve: from conceptual prompt to production-ready publication. The critical differentiator is not the tools themselves, but how they communicate.
📜 The Golden Rule: Just-in-Time (JIT) Source Modification
A pervasive anti-pattern in multi-platform AI workflows is downstream patching. When a sequence diagram fails validation in a desktop environment, engineers often manually edit the generated asset directly. This breaks the lineage between the source prompt and the published output, creating silent data drift and rendering future AI regenerations incompatible.
To preserve artifact integrity, adopt Just-in-Time (JIT) Source Modification:
-
Never Patch Downstream
Treat compiled artifacts as immutable outputs. If validation fails in the Desktop App or rendering breaks in OpenDocs, do not apply manual overrides in those environments. -
Return to the Source
Use ecosystem hyperlinks or embedded source pointers to launch the exact AI chatbot session or online editor context where the asset originated. -
Regenerate & Push
Adjust the prompt, parameters, or source text upstream. Allow the AI to rebuild the asset, then re-inject it into the pipeline. This guarantees that raw source files and deployment artifacts remain perfectly synchronized.
JIT modification transforms documentation from a fragile manual process into a resilient, auditable system.
📐 Diagram-to-Diagram Refinement Cascades
AI-driven architecture excels at progressive elaboration. Instead of forcing an LLM to generate a massive, monolithic system diagram in a single prompt, the pipeline leverages a structured Refinement Cascade. Each stage inherits context from the previous layer, reducing hallucination and increasing technical precision.
[Use Case Diagram] ➔ [Use Case Text] ➔ [Use Case Description] ➔ [Sequence Diagram]
1. High-Level Use Case Diagram
The AI chatbot ingests user requirements and system constraints to outline boundaries, actors, and primary goals. The output is a clean, high-level structural map.
2. Deep-Dive Use Case Specifications
The raw diagram nodes are passed to the online editor, where AI expands each actor-goal pair into granular, text-based use cases. This stage maps standard operational flows, preconditions, and success criteria.
3. Step-by-Step Use Case Descriptions
Semantic validation tools process the textual use cases, flattening them into structured tables or JSON schemas. Each entry details exact user actions, system responses, error handling, and state transitions.
4. Technical Sequence Diagram
Finally, the structured descriptions feed into an automated modeling engine. The engine translates sequential text into a precise sequence diagram, rendering object lifelines, API calls, async boundaries, and failure paths.
This cascade ensures that every technical diagram is traceable back to a business requirement, with AI handling the heavy lifting of format conversion and context inheritance.
🔗 Reusing Shared Artifacts Across Platforms
Maximizing portability requires strict adherence to ecosystem best practices. The following guidelines ensure artifacts move seamlessly between AI platforms, editors, and publishing engines without breaking JIT rules.
| Practice | Implementation | Benefit |
|---|---|---|
| Leverage Text-Based Formats | Store diagrams as code (Mermaid.js, PlantUML, D2, Structurizr) instead of raster/vector images. | Enables diffing, version control, AI parsing, and cross-platform rendering. |
| Embed Source Metadata | Append a cryptographic hash, short UUID, or deep-link URL to the footer of every artifact. | Provides instant traceability to the original prompt/editor context for JIT fixes. |
| Lock Downstream Permissions | Configure Pipeline Repository and OpenDocs as read-only mirrors for compiled assets. |
Enforces upstream-only edits, preventing unauthorized downstream patching. |
When combined, these practices create a self-healing documentation graph where every published page is a direct reflection of version-controlled source code.
🏗️ OpenDocs & Pipeline: The Synergy at the Core
The true power of this ecosystem emerges at the intersection of Pipeline Repository and OpenDocs. While often treated as separate tools, their combination forms the backbone of a scalable AI documentation architecture.
| Component | Responsibility | AI Ecosystem Integration |
|---|---|---|
| Pipeline Repository | Source control, CI/CD triggers, artifact staging, merge validation | Hosts AI-generated source files, runs automated diagram renderers, enforces JIT compliance via PR checks, triggers downstream builds. |
| OpenDocs | Static site generation, versioned publishing, search indexing, user-facing consumption | Pulls from pipeline artifacts, auto-renders text-based diagrams, injects source metadata, exposes read-only documentation portals. |
How They Work Together in the AI VP (Virtual Platform):
-
AI chatbots and editors commit markdown/diagram-as-code to the pipeline.
-
Pipeline CI jobs validate structure, run semantic linters, and compile preview builds.
-
Upon merge, OpenDocs fetches the latest tagged artifacts, regenerates the site, and publishes versioned documentation.
-
Readers access the OpenDocs portal. If they spot an error, the embedded source hash routes them back to the exact pipeline commit or editor session for JIT correction.
This closed loop transforms documentation from a maintenance burden into an automated, version-aware knowledge pipeline.
🛠️ Customizing the Blueprint for Your Stack
This architecture is platform-agnostic by design. To tailor it to your organization’s workflow, map the following variables to your existing toolchain:
🔹 Diagramming & Modeling Languages
Which syntax does your team standardize on? (e.g., Mermaid, PlantUML, D2, Miro API, Structurizr)
🔹 Hosting & Pipeline Infrastructure
What powers your version control and CI/CD orchestration? (e.g., GitHub Actions, GitLab CI, Bitbucket Pipelines, internal artifact servers)
🔹 AI Generation Stack
Which models or frameworks drive your automated drafting and refinement steps? (e.g., OpenAI, Anthropic, open-source LLMs via Ollama/vLLM, LangChain, custom RAG pipelines)
By aligning these three layers with the JIT modification rule and the refinement cascade, teams can deploy a documentation ecosystem that scales with their codebase, not against it.
✅ Conclusion
The AI documentation era demands more than better prompts; it requires better pipelines. By treating documentation as a series of versioned, traceable artifacts and enforcing Just-in-Time source modification, organizations can eliminate data drift, preserve architectural intent, and maintain a single source of truth across dozens of platforms.
When Pipeline Repository systems handle version control and validation, and OpenDocs serves as the immutable publication layer, AI-generated artifacts flow seamlessly from prompt to production. The result is documentation that evolves as rapidly as the software it describes—accurate, auditable, and endlessly reusable.
Ready to architect your AI documentation pipeline? Map your diagramming standards, pipeline infrastructure, and AI models to this blueprint, and transform scattered drafts into a unified knowledge ecosystem.
